AI - How to set it up in NovelForge






























Setting up a local LLM or using cloud AI is actually pretty simple, so don’t worry! There’s not much involved.
OpenRouter is a great cloud platform that gives you access to multiple AI models. Instead of a
subscription, it uses a pre-paid credit system.
But don’t worry, Openrouter also has plenty of free options too and you don’t even need to
purchase any credits.
First you need to register on OpenRouter. Just head to https://openrouter.ai/ and sign up.
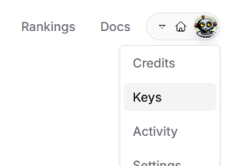
Once you're signed in, click on the menu in the top-right corner (where your profile picture is) and
select "Keys."
Openrouter - the simplest method
This is where you can create an API key. If you’re not familiar with API keys, don’t stress, it’s just
a long string of letters and numbers that identifies your account.
When you make a request through a software such as NovelForge this API key is passed along so
OpenRouter server knows it’s you.
Think of it as a far more secure alternative to sending your email or user name.
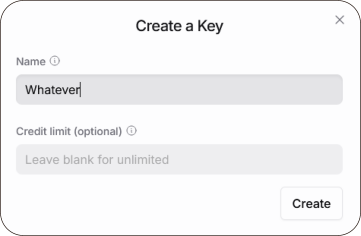
Creating an API key is as hard as pressing the Create Key button.
There’s no limit to how many you can generate, and you can delete
or create new ones whenever you want. They simply serve as
anonymous identifiers for your account.

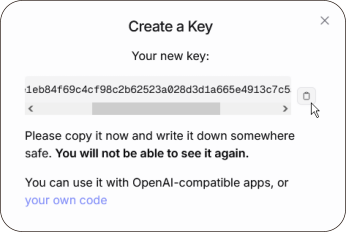
One important thing to remember: You can
only see and copy the API key string at the
moment you create it.
After that, it’s hidden for security reasons.
So make sure to copy it at this time or you
will need to create a new API key if you
don’t.
That’s all there is to it. Now you have access to AI! Now let’s go to NovelForge
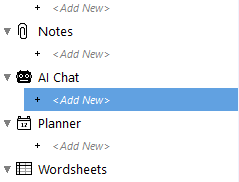
On the project menu find the
AI Chat option and double
click on the <Add New>
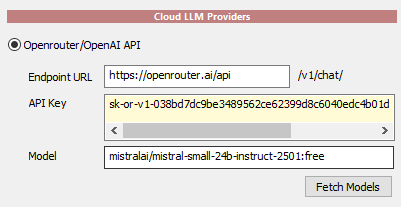
On the new chat window press Server
Settings
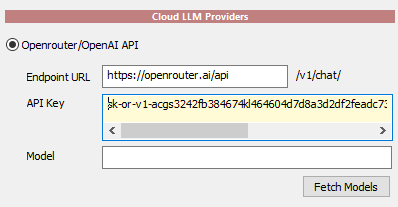
Now paste your freshly obtained API key in
the Cloud LLM Providers section
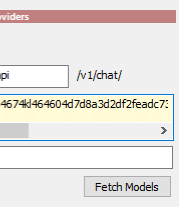
Press Fetch Models button
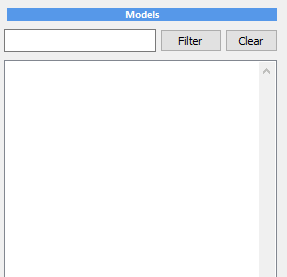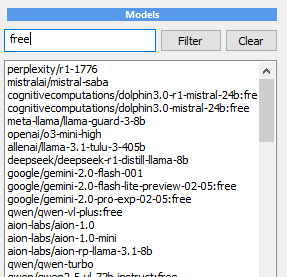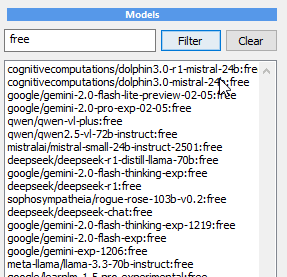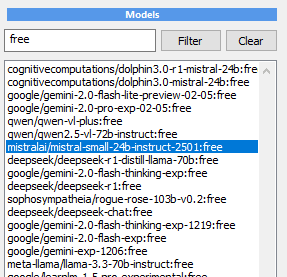
If everything is all right,
this should populate the
Models window with all the
available models.
Pick a free model. You can try a few but note, the
free versions of many 70b models are usually
slow and busy, so chosing smaller 24b model will
give you much faster response. Google’s
google/gemini-2.0-flash-exp:free could be a good
choice for a SOTA model too!
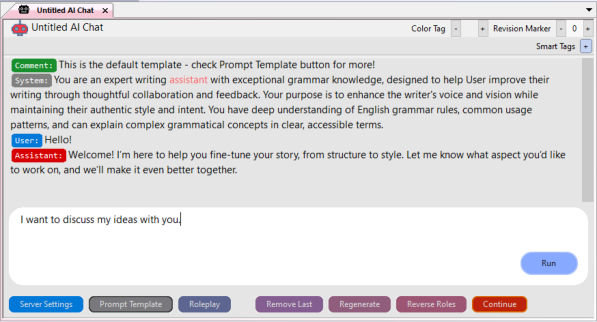
You can start chatting!
Unlike a regular chat, NovelForge lets you type in both the
bottom and top windows.
Whatever you type in the bottom window is the message that
the AI will receive.
The top window serves as prior context—the text the AI sees
before your message, shaping its style and alignment.
This free-form typing system opens up a lot of possibilities, but
we’ll dive deeper into that in future tutorials.
Fully local solution setup
You can also host your own AI server, just note that the experience will depend on how powerful your computer is (and if it has GPU or not)
However many smaller models (like llama3-3B) can work even on CPU thanks to big optimizations that happened over the last few years.
The absolute easiest way would be to use LM Studio, then Ollama while using Oobabooga WebUI needs a bit more involvement.
Head to https://lmstudio.ai/ and download the LM Studio for Windows and install it. It’s really user friendly!
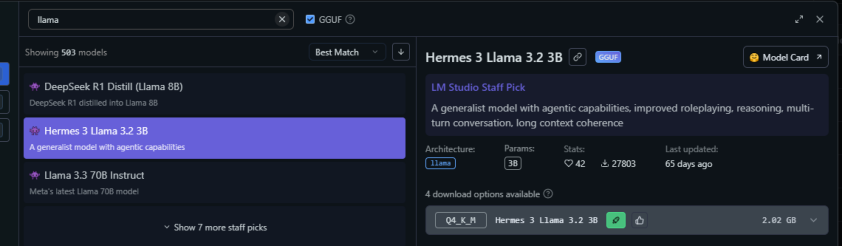
Once you install it you need to download a model. I’d suggest start with something small and fast such as Hermes 3 Llama 3.2 3B. So go to the
Discover tab (the icon looks like a magnifying lens) and find the Hermes 3 3B and hirt download. It will be about 2GB.
The Easiest way - LM Studio
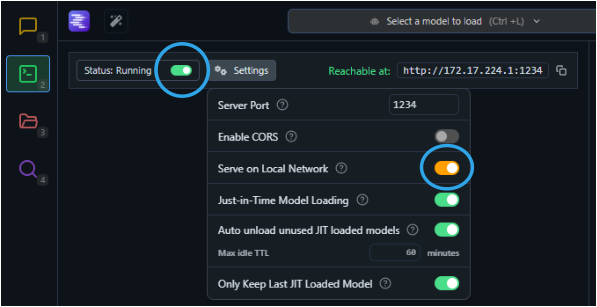
Move to the Developer tab and set the swith to Status Running. Click on the
Settings button and select Serve on Local Network.
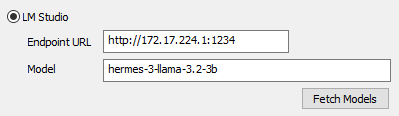
Once the model is downloaded, go to NovelForge and this
time select LM Studio option in the Server Settings. Use the
URL that is shown on the right side in the Developer tab
and press Fetch Models which should show your
downloaded model. Select it.
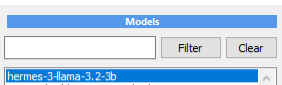
Now type ‘free’ in the find box and
press Filter to see only free models.
(They might change form time to
time)
Now you can start chatting! Just keep in mind that the first time you send a message, if the model isn’t already loaded into memory, LM
Studio will need to load it. This might take a little time. You can check the LM Studio Developer interface to see the loading progress.
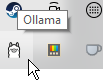
Ollama - the lightweight solution
Ollama https://ollama.com/ could be also a good option for local Ai since it is build as a lightweight solution written for
precisely this type of use. Once installed it sits in the tray area, doing nothing. Unlike LM Studio you communicate with it
through command line as it doesn’t have any interface.
‘
‘http://127.0.0.1:11434 is the typical URL of your ollama installation. Now to download
models you need to use the CMD button which will open the terminal window.
Look at the ollama site to see the names of models they are direclty supporting.
In this case I want to load the llama 3.2 3B, which the ollama site tells me I need to
run it with: ollama run llama3.2
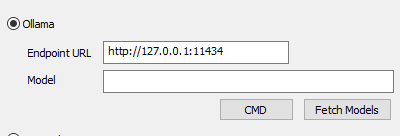
In the commandline that opened just type: ollama run llama3.2
This will download the llama3.2 model and load it in memory. Once it is done, you can close the terminal window and press Fetch Models.
The model should appear in the list so you can now select it.
Again, remember, the first message will need to load the model to the memory so it will take a little time for it to appear.
WebUI- the heavyweight
Installing and using WebUI is a bit more involved as it requires python, but WebUI can support many different models and has far more detailed
options. There is a comprehensive guide on the github pages https://github.com/oobabooga/text-generation-webui
Recommended Models for GPU:
(it depends on your GPU)
•
Mistral Nemo 2407
•
Mistral-Small-24B-Instruct-2501-GGUF
•
Mistral-Small-Drummer-22B-GGUF (prose)
•
Qwen2.5-7B-Instruct-1M-GGUF (large context)
Can this run on laptop without any dedicated GPU?
You can definitely run smaller models on just a CPU, but performance depends on your computer. The bigger the model, the slower the
response, to the point where it might become unusable. In general speed of 7B models feels like you are texting with someone in real time.
3B models like Llama 3.2 3B perform relatively well and remain usable.. That said, the Llama 3.2 3B model punches above its weight as it’s
surprisingly capable for its size. Even if you were stranded on a deserted island with no internet, it would still feel like having access to
information!
(Note: 1B models are more of a novelty and generally not very usable due to their drop in quality.)
When comparing Ollama and LM Studio on CPU, I found Ollama to be faster and more responsive overall. However, some models didn’t perform
as well, for instance, Hermes 3 3B in Ollama had issues with misspelled words and memory retention, whereas it worked fine in LM Studio.
Recommended Models for CPU:
•
LM Studio: Llama 3.2 3B, Hermes 3 Llama 3.2 3B
•
google/gemma-4-E4B (it’s almost magical for the size)
•
Ollama: Llama 3.2 3B (surprisingly fast), Mistral 7B (rather slow, but still somehow usable)











Recomended Free models:
The free models might change over time.
•
google/gemini-2.0-flash-exp:free
•
nvidia/llama-3.1-nemotron-70b-instruct:free
•
cognitivecomputations/dolphin3.0-mistral-24b:free
•
meta-llama/llama-3.1-8b-instruct:free
•
mistralai/mistral-7b-instruct:free
•
DeepSeek-R1-Distill-Llama-8B-GGUF (reasoning model)
•
Qwen2.5-14B-Instruct-GGUF
•
EVA-Qwen2.5-14B-v0.2-GGUF (long prose)
•
Meta-Llama-3.1-8B-Instruct-GGUF



Note:
For Google Studio API use URL:
https://generativelanguage.googleapis.com/v1beta/openai
If you are using this guide for setting up Editorial, please note in
Editorial we went with a more strict base url, so you need to specify the
full url, example for openrouter: https://openrouter.ai/api/v1

A new book from the author of NovelForge: Learn How to Train and Run Your Own Language Models at Home
After years of hacking away at open-source AI, I decided to write everything down. The good, the bad, and
the messy truths no glossy tutorial will tell you. The result is a 600-page, no-nonsense guide to training and
running language models locally, on your own hardware, without cloud dependencies or corporate
gatekeepers.